имеется код (p/s, я новичок в python):
headers = {
"user-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"
}
browser = webdriver.Chrome()
url = "https://portal.eaeunion.org/sites/o...475-466a-a340-6f69c01b5687&itemid=231#f=g-150"
browser.get(url)
time.sleep(10)
html = browser.page_source
soup = BeautifulSoup(html, 'lxml')
trs = soup.find('div', class_='cr-view cr-bottom-view').find('table', class_='table').find('tbody').find_all('tr')
table = pd.DataFrame()
for tr in trs:
numb_doc = tr.find_all('td', {"name": "tmp_RegisterCertificatesStateRegistration_NUMB_DOC"})
for i in numb_doc:
numb_doc = i.text.replace('\n', '')
# print(numb_doc)
status = tr.find_all('td', {"name": "Status"})
for i in status:
status = i.text.replace('\n', '')
# print(status)
date_doc = tr.find_all('td', {"name": "tmp_RegisterCertificatesStateRegistration_DATE_DOC"})
for i in date_doc:
date_doc = i.text.replace('\n', '')
# print(date_doc)
name_prod = tr.find_all('td', {"name": "tmp_RegisterCertificatesStateRegistration_NAME_PROD"})
for i in name_prod:
name_prod = i.text.replace('\n', '')
# print(name_prod)
firmmade_name = tr.find_all('td', {"name": "tmp_RegisterCertificatesStateRegistration_FIRMMADE_NAME"})
for i in firmmade_name:
firmmade_name = i.text.replace('\n', '')
# print(firmmade_name)
firmget_name = tr.find_all('td', {"name": "tmp_RegisterCertificatesStateRegistration_FIRMGET_NAME"})
for i in firmget_name:
firmget_name = i.text.replace('\n', '')
# print(firmget_name)
doc_usearea = tr.find_all('td', {"name": "tmp_RegisterCertificatesStateRegistration_DOC_USEAREA"})
for i in doc_usearea:
doc_usearea = i.text.replace('\n', '')
# print(doc_usearea)
data_s = [numb_doc, status, date_doc, name_prod, firmmade_name, firmget_name, doc_usearea]
with open("rez.csv", 'a', newline="") as file:
writer = csv.writer(file)
writer.writerow(data_s)
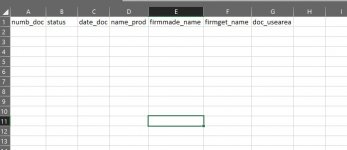
как вывести data_s в csv в виде:
т.е. каждое значение в отдельный столбец
p/s код с отступами во вложении
headers = {
"user-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"
}
browser = webdriver.Chrome()
url = "https://portal.eaeunion.org/sites/o...475-466a-a340-6f69c01b5687&itemid=231#f=g-150"
browser.get(url)
time.sleep(10)
html = browser.page_source
soup = BeautifulSoup(html, 'lxml')
trs = soup.find('div', class_='cr-view cr-bottom-view').find('table', class_='table').find('tbody').find_all('tr')
table = pd.DataFrame()
for tr in trs:
numb_doc = tr.find_all('td', {"name": "tmp_RegisterCertificatesStateRegistration_NUMB_DOC"})
for i in numb_doc:
numb_doc = i.text.replace('\n', '')
# print(numb_doc)
status = tr.find_all('td', {"name": "Status"})
for i in status:
status = i.text.replace('\n', '')
# print(status)
date_doc = tr.find_all('td', {"name": "tmp_RegisterCertificatesStateRegistration_DATE_DOC"})
for i in date_doc:
date_doc = i.text.replace('\n', '')
# print(date_doc)
name_prod = tr.find_all('td', {"name": "tmp_RegisterCertificatesStateRegistration_NAME_PROD"})
for i in name_prod:
name_prod = i.text.replace('\n', '')
# print(name_prod)
firmmade_name = tr.find_all('td', {"name": "tmp_RegisterCertificatesStateRegistration_FIRMMADE_NAME"})
for i in firmmade_name:
firmmade_name = i.text.replace('\n', '')
# print(firmmade_name)
firmget_name = tr.find_all('td', {"name": "tmp_RegisterCertificatesStateRegistration_FIRMGET_NAME"})
for i in firmget_name:
firmget_name = i.text.replace('\n', '')
# print(firmget_name)
doc_usearea = tr.find_all('td', {"name": "tmp_RegisterCertificatesStateRegistration_DOC_USEAREA"})
for i in doc_usearea:
doc_usearea = i.text.replace('\n', '')
# print(doc_usearea)
data_s = [numb_doc, status, date_doc, name_prod, firmmade_name, firmget_name, doc_usearea]
with open("rez.csv", 'a', newline="") as file:
writer = csv.writer(file)
writer.writerow(data_s)
как вывести data_s в csv в виде:
| numb_doc | status | date_doc | name_prod | firmmade_name | firmget_name | doc_usearea |
т.е. каждое значение в отдельный столбец
p/s код с отступами во вложении
Вложения
Последнее редактирование:


")