Добрый день.
Прошу помощи, какие методы использовать.
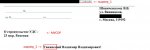
Переменная text содержит текстовый контент, сформированный путём распознавания текста на изображение, используя tesseract
переменная text выводит контент примерно следующего содержания:
Задача: удалить весь текст до МАРКЕР_1 и после МАРКЕР_2, оставив то, что между этими маркерами т.е. НУЖНЫЙ КОНТЕНТ
Прошу помощи, какие методы использовать.
Переменная text содержит текстовый контент, сформированный путём распознавания текста на изображение, используя tesseract
Python:
from PIL import Image
import pytesseract
import string
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract.exe'
im = Image.open("Screens/test2.jpg")
text = pytesseract.image_to_string(im, lang = 'rus')
print(text)переменная text выводит контент примерно следующего содержания:
Код:
ненужный текстовый контент МАРКЕР_1
НУЖНЫЙ КОНТЕНТ
МАРКЕР_2 ненужный текстовый контентЗадача: удалить весь текст до МАРКЕР_1 и после МАРКЕР_2, оставив то, что между этими маркерами т.е. НУЖНЫЙ КОНТЕНТ