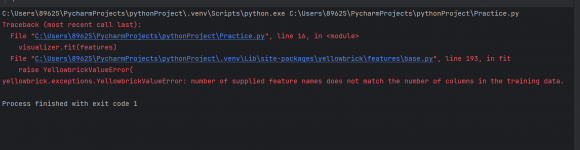
почему то не идет чтение из файла, помогите понять в чем ошибка и как ее исправить (все библиотеки установлены)
выводит, что ошибка в 12 строке ( File "C:\Users\89625\PycharmProjects\pythonProject\Practice.py", line 12, in <module>
data = pd.read_csv('data.csv'))
не понимаю в чем проблема, файл (для чтения) находится в той же директории, что и код
выводит, что ошибка в 12 строке ( File "C:\Users\89625\PycharmProjects\pythonProject\Practice.py", line 12, in <module>
data = pd.read_csv('data.csv'))
не понимаю в чем проблема, файл (для чтения) находится в той же директории, что и код
Python:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from yellowbrick.features import Rank2D
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.feature_selection import SelectKBest, f_regression
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import r2_score
data = pd.read_csv('data.csv')
features = data[['y', 'x1', 'x2', 'x3', 'x4', 'x5', 'x6']]
visualizer = Rank2D(features=features, algorithm='pearson')
visualizer.fit(features)
visualizer.transform(features)
visualizer.show()
plt.figure(figsize=(10, 8))
sns.heatmap(data.corr(), annot=True, cmap='coolwarm')
plt.show()
scaler = StandardScaler()
data[['y', 'x1', 'x2', 'x3', 'x4', 'x5', 'x6']] = scaler.fit_transform(data[['y', 'x1', 'x2', 'x3', 'x4', 'x5', 'x6']])
X = data[['x1', 'x2', 'x3', 'x4', 'x5', 'x6']]
y = data['y']
model = LinearRegression()
model.fit(X, y)
predicted_values = model.predict(X)
selector = SelectKBest(score_func=f_regression, k=3)
X_new = selector.fit_transform(X, y)
selected_features = X.columns[selector.get_support()]
model_knn = KNeighborsRegressor()
model_knn.fit(X, y)
predicted_values_knn = model_knn.predict(X)
model_tree = DecisionTreeRegressor()
model_tree.fit(X, y)
predicted_values_tree = model_tree.predict(X)
r2_linear = r2_score(y, predicted_values)
r2_knn = r2_score(y, predicted_values_knn)
r2_tree = r2_score(y, predicted_values_tree)
best_model = max(r2_linear, r2_knn, r2_tree)
plt.figure(figsize=(10, 8))
plt.scatter(y, y - predicted_values, color='blue', label='Linear Regression')
plt.axhline(y=0, color='r', linestyle='-')
plt.xlabel('Actual values')
plt.ylabel('Residuals')
plt.legend()
plt.show()
if best_model == r2_linear:
print("Best model: Linear Regression")
elif best_model == r2_knn:
print("Best model: K-Nearest Neighbors")
else:
print("Best model: Decision Tree")