я работаю над парсингом сайта на питоне, использую библиотеки(requests, BS4, csv)p.s все последних версий. система: винда, питон - 3.9. ПРОБЛЕМА - мне нужно спарсить несколько параметров с карточки товара и у меня получилось спарсить всё кроме цены. как только я прописал метод(get_text), мне вылетела ошибка - AttributeError: 'NoneType' object has no attribute 'get_text'. после этого я несколько раз проверил класс и тег, всё оказалось верно. без (get_text) всё работает.
на данный момент прога работает, две строки с ошибкой в комментариях.
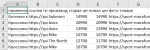
и часть кода сайта по цене:
на данный момент прога работает, две строки с ошибкой в комментариях.
Python:
import requests
from bs4 import BeautifulSoup
import csv
URL = 'https://sport-marafon.ru/catalog/muzhskie-krossovki/'
HEADERS = {'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Mobile Safari/537.36', 'accept': '*/*'}
HOST = 'https://sport-marafon.ru'
CSV = 'shoes.csv'
def save_content(items, path):
with open(path, 'w', newline='') as file:
writer = csv.writer(file, delimiter=';')
writer.writerow(['наименование', 'ссылка товара', 'производитель', 'фото товара'])
for item in items:
writer.writerow([item['название'], item['ссылка'], item['бренд'], item['картинка']])
def get_content(html):
soup = BeautifulSoup(html, 'html.parser')
items = soup.find_all('div', class_='col-6 col-md-4 col-lg-4')
shoes = []
for item in items:
shoes.append({
'название': item.find('a', class_='product-list__name').get_text(),
'ссылка': HOST + item.find('a').get('href'),
'бренд': item.find('a', class_='product-list__brand').get_text(),
#'цена без скидки': item.find('div', class_='product-list__price product-list__price_old').get_text(),
#'цена со скидкой': item.find('div', class_='product-list__price product-list__price_new').get_text(),
'картинка': HOST + item.find('div', class_='product-list__image-wrap').find('img').get('src'),
})
return shoes
def get_html(url, params=''):
r = requests.get(url, headers=HEADERS, params=params)
return r
def parse():
PAGENATION = input('укажите кол-во страниц для парсинга: ')
PAGENATION = int(PAGENATION.strip())
html = get_html(URL)
if html.status_code == 200:
shoes = []
for page in range(0, PAGENATION):
print(f'идёт парсинг страницы: {page}')
html = get_html(URL, params={'page': page})
shoes.extend(get_content(html.text))
save_content(shoes, CSV)
else:
print('Не удаётся получить доступ к сайту!')
parse()
HTML:
<div data-v-49001340="" class="product-list__price product-list__price_new">
8 393 ₽
</div>
<div data-v-49001340="" class="product-list__price product-list__price_old">11 990 ₽
</div>
Последнее редактирование: