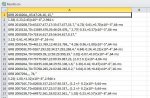
Доброго времени суток!
Не первый раз к вам обращаюсь и на сей раз вопросы такие. Я записываю собранную с сайтов информацию в файл Excel следующим образом:
И в целом все получается. Но есть несколько мелочей, которые хотелось бы поправить и я не знаю, как: Вот они:
1. Как в duration добавить 'duration of~', 'duration of ~ ', чтобы выборка шла следующим образом: или находим 'duration of ~' или 'duration of ~ ' или 'duration of~ '?
2. Как сделать, чтобы данные по GRB 201020A, GRB 200920B, GRB 200729A были на 1 строчке, а не двух?
3. Как убрать кавычки (" ") у некоторых значений fluence?
4. Как сделать каждое значение (b_name, starttime, fluence и т.д.) в своем столбце (сейчас они все в одном)?
Работаю на Python 3.9.0. Скриншот того, что у меня получается сейчас прилагаю.
Заранее спасибо за помощь!
Не первый раз к вам обращаюсь и на сей раз вопросы такие. Я записываю собранную с сайтов информацию в файл Excel следующим образом:
Код:
from bs4 import BeautifulSoup
import requests
import re
import csv
def write_csv(data):
with open('Results.csv', 'a') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow((data['b_name'],
data['starttime'],
data['starttimeUT'],
data['duration'],
data['fluence'],
data['peak_fl']))
with open("List_of_links.txt") as f:
lines = [line.rstrip('\n') for line in f]
for line in lines:
response = requests.get(line)
soup = BeautifulSoup(response.content, "lxml")
ptag = soup.find(lambda tag: tag.name == 'p')
string = str(ptag)
b_name = re.search('GRB \d{6}\w', string)
if b_name != None:
print(b_name.group(0))
else:
print('None')
starttime = re.findall('T0=\d{1,5}.\d{1,5}', string)
if starttime != None:
print(starttime)
else:
print('None')
starttimeUT = re.findall('\d{2}:\d{2}:\d{2}.\d{1,5}', string)
if starttimeUT != None:
print(starttimeUT)
else:
print('None')
duration = string[string.find('duration of ~'):string.find(' s.')]
if duration != None:
print(duration[duration.find('~'):])
else:
print('None')
fluence = string[string.find('fluence of'):string.find(' erg/')]
if fluence != None:
print(fluence[fluence.find('of ') + 3:])
else:
print('None')
peak_fl = re.search(('\d{1}.\d{1,3}-s |\d{1,3}-ms'), string)
if peak_fl != None:
print(peak_fl.group(0))
else:
print('None')
data={'b_name':b_name.group(),
'starttime':string.join(starttime),
'starttimeUT':string.join(starttimeUT),
'duration':duration.replace('duration of ~', ''),
'fluence':fluence.replace('fluence of', ''),
'peak_fl':peak_fl.group()}
write_csv(data)1. Как в duration добавить 'duration of~', 'duration of ~ ', чтобы выборка шла следующим образом: или находим 'duration of ~' или 'duration of ~ ' или 'duration of~ '?
2. Как сделать, чтобы данные по GRB 201020A, GRB 200920B, GRB 200729A были на 1 строчке, а не двух?
3. Как убрать кавычки (" ") у некоторых значений fluence?
4. Как сделать каждое значение (b_name, starttime, fluence и т.д.) в своем столбце (сейчас они все в одном)?
Работаю на Python 3.9.0. Скриншот того, что у меня получается сейчас прилагаю.
Заранее спасибо за помощь!