Добрый день, я нашел пример кода с парсером который парсит сайт, берет от туда название статьи, ссылку на неё и краткое описание и записывает эти данные в JSON файл. Я немного переделал это под свой сайт который мне надо, но конечно же всё работает не совсем так как надо. После записи данные title и desc записываются одинаково для всех статей, а с url и id всё нормально и как надо. Помогите пожалуйста решить проблему. Буду очень благодарен.
Вот код:
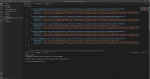
А вот результат записи на json
Вот код:
Код:
import json
import requests
from bs4 import BeautifulSoup
# --- NEW VOKEBLULARY ---------------------------------------------------------------- NEW VOKEBLULARY --------------------
def get_first_news():
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64"
}
url = "https://bmr.gov.ua/index.php?id=2&no_cache=1"
r = requests.get(url=url, headers=headers)
soup = BeautifulSoup(r.text, "lxml")
articles_cards = soup.find_all("div", class_="article articletype-0")
news_dict = {}
for article in articles_cards:
article_title = article.find("h3").text.strip()
article_desc = article.find("p").text.strip()
for i in soup.find_all('a', class_='more', href=True):
article_url = (f'https://bmr.gov.ua/{i["href"]}')
article_id = article_url.split("/")[-1]
# print(f"{article_title} | {article_url}")
news_dict[article_id] = {
"article_title": article_title,
"article_url": article_url,
"article_desc": article_desc
}
with open("news_dict.json", "w", encoding='utf-8') as file:
json.dump(news_dict, file, indent=4, ensure_ascii=False)А вот результат записи на json