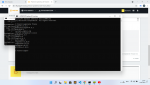
Ошибка в 17 строчке.
^
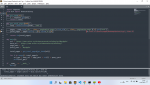
Код:
import requests
from bs4 import BeautifulSoup
# План:
# 1. Выяснить количество страниц.
# 2. Сформировать список url на страницы выдачи.
# 3. Собрать данные.
def get_html(url):
r = requests.get(url)
return r.text
def get_total_pages(html):
soup = BeautifulSoup(html, 'lxml')
pages = soup.find('div', class_='pagination-pages').find_all('a', class_='pagination-page')[-1].get('href')
total_pages = pages.split('=')[2].split('&')[0]
return int(total_pages)
def main():
url = 'https://www.avito.ru/nizhnevartovsk/telefony?p=1&q=Apple'
base_url = 'https://www.avito.ru/nizhnevartovsk/telefony?'
page_part = 'p='
query_part = '&q=Apple'
total_pages = get_total_pages(get_html(url))
for i in range(1, total_pages):
url_gen = base_url + page_part + str(i) + query_part
print(url_gen)
if __name__ == '__main__':
main()^
Вложения
Последнее редактирование:
.png")
